Chris Lamb: Favourite books of 2022: Memoir/biography
 In my two most recent posts, I listed the fiction and classic fiction I enjoyed the most in 2022.
I'll leave my roundup of general non-fiction until tomorrow, but today I'll be going over my favourite memoirs and biographies, in no particular order.
Books that just missed the cut here include Roisin Kiberd's The Disconnect: A Personal Journey Through the Internet (2019), Steve Richards' The Prime Ministers (2019) which reflects on UK leadership from Harold Wilson to Boris Johnson, Robert Graves Great War memoir Goodbye to All That (1929) and David Mikics's portrait of Stanley Kubrick called American Filmmaker.
In my two most recent posts, I listed the fiction and classic fiction I enjoyed the most in 2022.
I'll leave my roundup of general non-fiction until tomorrow, but today I'll be going over my favourite memoirs and biographies, in no particular order.
Books that just missed the cut here include Roisin Kiberd's The Disconnect: A Personal Journey Through the Internet (2019), Steve Richards' The Prime Ministers (2019) which reflects on UK leadership from Harold Wilson to Boris Johnson, Robert Graves Great War memoir Goodbye to All That (1929) and David Mikics's portrait of Stanley Kubrick called American Filmmaker.
Afropean: Notes from Black Europe (2019) Johny Pitts Johny Pitts is a photographer and writer who lives in the north of England who set out to explore "black Europe from the street up" those districts within European cities that, although they were once 'white spaces' in the past, they are now occupied by Black people. Unhappy with the framing of the Black experience back home in post-industrial Sheffield, Pitts decided to become a nomad and goes abroad to seek out the sense of belonging he cannot find in post-Brexit Britain, and Afropean details his journey through Paris, Brussels, Lisbon, Berlin, Stockholm and Moscow. However, Pitts isn't just avoiding the polarisation and structural racism embedded in contemporary British life. Rather, he is seeking a kind of super-national community that transcends the reductive and limiting nationalisms of all European countries, most of which have based their national story on a self-serving mix of nostalgia and postcolonial fairy tales. Indeed, the term 'Afropean' is the key to understanding the goal of this captivating memoir. Pitts writes at the beginning of this book that the word wasn't driven only as a response to the crude nativisms of Nigel Farage and Marine Le Pen, but that it:
encouraged me to think of myself as whole and unhyphenated. [ ] Here was a space where blackness was taking part in shaping European identity at large. It suggested the possibility of living in and with more than one idea: Africa and Europe, or, by extension, the Global South and the West, without being mixed-this, half-that or black-other. That being black in Europe didn t necessarily mean being an immigrant.In search of this whole new theory of home, Pitts travels to the infamous banlieue of Clichy-sous-Bois just to the East of Paris, thence to Matong in Brussels, as well as a quick and abortive trip into Moscow and other parallel communities throughout the continent. In these disparate environs, Pitts strikes up countless conversations with regular folk in order to hear their quotidian stories of living, and ultimately to move away from the idea that Black history is defined exclusively by slavery. Indeed, to Pitts, the idea of race is one that ultimately restricts one's humanity; the concept "is often forced to embody and speak for certain ideas, despite the fact it can't ever hold in both hands the full spectrum of a human life and the cultural nuances it creates." It's difficult to do justice to the effectiveness of the conversations Pitts has throughout his travels, but his shrewd attention to demeanour, language, raiment and expression vividly brings alive the people he talks to. Of related interest to fellow Brits as well are the many astute observations and comparisons with Black and working-class British life. The tone shifts quite often throughout this book. There might be an amusing aside one minute, such as the portrait of an African American tourist in Paris to whom "the whole city was a film set, with even its homeless people appearing to him as something oddly picturesque." But the register abruptly changes when he visits Clichy-sous-Bois on an anniversary of important to the area, and an element of genuine danger is introduced when Johny briefly visits Moscow and barely gets out alive. What's especially remarkable about this book is there is a freshness to Pitt s treatment of many well-worn subjects. This can be seen in his account of Belgium under the reign of Leopold II, the history of Portuguese colonialism (actually mostly unknown to me), as well in the way Pitts' own attitude to contemporary anti-fascist movements changes throughout an Antifa march. This chapter was an especial delight, and not only because it underlined just how much of Johny's trip was an inner journey of an author willing have his mind changed. Although Johny travels alone throughout his journey, in the second half of the book, Pitts becomes increasingly accompanied by a number of Black intellectuals by the selective citing of Frantz Fanon and James Baldwin and Caryl Phillips. (Nevertheless, Jonny has also brought his camera for the journey as well, adding a personal touch to this already highly-intimate book.) I suspect that his increasing exercise of Black intellectual writing in the latter half of the book may be because Pitts' hopes about 'Afropean' existence ever becoming a reality are continually dashed and undercut. The unity among potential Afropeans appears more-and-more unrealisable as the narrative unfolds, the various reasons of which Johny explores both prosaically and poetically. Indeed, by the end of the book, it's unclear whether Johny has managed to find what he left the shores of England to find. But his mix of history, sociology and observation of other cultures right on my doorstep was something of a revelation to me.
Orwell's Roses (2021)
Rebecca Solnit
Orwell s Roses is an alternative journey through the life and afterlife of George Orwell, reimaging his life primarily through the lens of his attentiveness to nature. Yet this framing of the book as an 'alternative' history is only revisionist if we compare it to the usual view of Orwell as a bastion of 'free speech' and English 'common sense' the roses of the title of this book were very much planted by Orwell in his Hertfordshire garden in 1936, and his yearning of nature one was one of the many constants throughout his life. Indeed, Orwell wrote about wildlife and outdoor life whenever he could get away with it, taking pleasure in a blackbird's song and waxing nostalgically about the English countryside in his 1939 novel Coming Up for Air (reviewed yesterday).
 By sheer chance, I actually visited this exact garden immediately to the publication of this book
By sheer chance, I actually visited this exact garden immediately to the publication of this book
The Disaster Artist (2013)
Greg Sestero & Tom Bissell
For those not already in the know, The Room was a 2003 film by director-producer-writer-actor Tommy Wiseau, an inscrutable Polish immigr with an impenetrable background, an idiosyncratic choice of wardrobe and a mysterious large source of income. The film, which centres on a melodramatic love triangle, has since been described by several commentators and publications as one of the worst films ever made.
Tommy's production completely bombed at the so-called 'box office' (the release was actually funded entirely by Wiseau personally), but the film slowly became a favourite at cult cinema screenings. Given Tommy's prominent and central role in the film, there was always an inherent cruelty involved in indulging in the spectacle of The Room the audience was laughing because the film was astonishingly bad, of course, but Wiseau infused his film with sincere earnestness that in a heartless twist of irony may be precisely why it is so terrible to begin with. Indeed, it should be stressed that The Room is not simply a 'bad' film, and therefore not worth paying any attention to: it is uncannily bad in a way that makes it eerily compelling to watch. It unintentionally subverts all the rules of filmmaking in a way that captivates the attention. Take this representative example:

 Holger Levsen: Welcome, David, thanks for taking the time to talk with us today. First, could you briefly tell me about yourself?
David: Sure! I m David A. Wheeler and
I work for the
Holger Levsen: Welcome, David, thanks for taking the time to talk with us today. First, could you briefly tell me about yourself?
David: Sure! I m David A. Wheeler and
I work for the 
 A few days ago, my home network got a refresh that resulted in the enablement of some next-generation
technologies for me and my family. Well, next-generation or current-generation, depending on your point of view.
Per the ISP standards in Spain (my country), what I ll describe next is literally the most and latest you can get.
The post title spoiled it already. I have now 10G internet uplink and native IPv6 since I changed my ISP to
A few days ago, my home network got a refresh that resulted in the enablement of some next-generation
technologies for me and my family. Well, next-generation or current-generation, depending on your point of view.
Per the ISP standards in Spain (my country), what I ll describe next is literally the most and latest you can get.
The post title spoiled it already. I have now 10G internet uplink and native IPv6 since I changed my ISP to 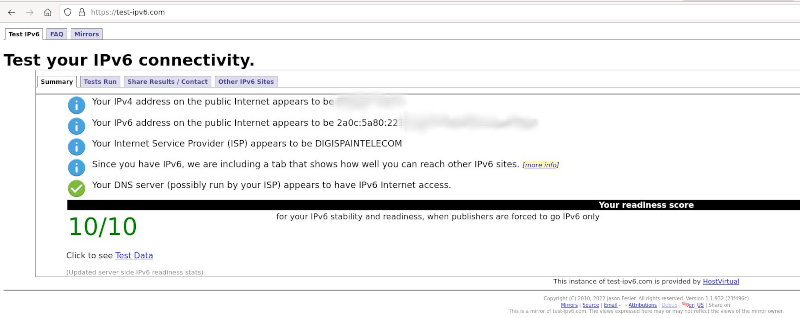 If you are curious, this was the IPv6 prefix whois information:
If you are curious, this was the IPv6 prefix whois information:






 Updates
Back in April I wrote about
Updates
Back in April I wrote about
 After I wrote
After I wrote